从高密度表面肌电数据中解码无声语音识别(SSR)
导读
最近,基于表面肌电图(sEMG)的无声语音识别(SSR)研究是通过对有限数量的单词或短语进行分类来进行的,与在细粒度音节或音素水平上的顺序解码相比,对形成中的时间语义没有足够的理解。本文提出了一种基于sEMG的SSR的音节级序列解码方法,该方法使用变换器模型。所提出的方法由一个转换器模型和一个语言模型组成。变换器模型首先将输入的sEMG数据转换为音节级决策序列。然后,这些顺序的音节级决策被调整为最终的音节序列,以通过语言模型近似自然语言。为了验证所提出的方法的有效性,在对82个音节的词典中生成的33个汉语短语进行潜读时,使用两个64通道的高密度电极阵列记录了来自总共8名受试者的实验数据。该方法的字符错误率最低,为5.14±3.28%,短语识别准确率最高,为96.37±2.06%,显著优于其他基于表面肌电信号的SSR常用方法。这些发现证明了所提出的方法在实际SSR应用中的可行性和可用性。
介绍
言语作为一种自然有效的人类交流方式,能够包含和传递有意义的语义信息。近年来,随着计算机科学技术的飞速发展,自动语音识别(ASR)技术作为一种很有前途的人机交互方式受到了广泛的关注。ASR系统通过计算机将语音信号转换为文本符号。通过将语音识别接口集成到手机、手表、汽车等智能设备中,语音识别已经广泛应用于人们的日常生活中。
然而,该技术在实际应用中仍面临一些挑战。首先,ASR并不适用于有言语障碍的人。第二,在交流中存在个人隐私的安全问题。最后,在恶劣的声环境下,即有噪声的条件下,ASR的性能会受到影响。为了解决ASR的这些局限性,一种基于非声学信号的无声语音识别技术被提出。SSR利用各种生理指标来检测人类语言相关活动,然后解码其语义信息。它能够精确地识别语音,而不需要声音。这些生理测量是通过感知无声言语活动中的各种生物信而获得的,如表面肌电图(sEMG)、脑电图(EEG)、永磁或电磁关节成像(PMA或EMA)、唇读等。从本质上讲,言语是由与发音相关的关节肌肉的神经肌肉活动产生的。表面肌电信号可以通过在人体皮肤表面放置电极来测量电信号来反映肌肉活动模式。它操作简单,无创。因此,表面肌电信号在SSR的实际应用中具有很大的潜力。
最初,一些基于表面肌电信号的SSR研究试图使用简单的模式识别算法对sepa(表面肌电信号)率词进行分类。以下列出了一些具有代表性的研究:Chan等人使用线性判别(LDA)对从受试者颈部和面部肌肉中收集的十个数字0-9的表面肌电信号进行分类,并在听觉实验中实现了7%的单词错误率(WER)。子序研报道了用隐马尔可夫模型(HMM)分别建立独立的韩语词进行模式分类,识别准确率为87.08%。后来,用9个分类器来识别阿拉伯语中三个最难的元音。结果表明,随机森林分类器的分类正确率为77%。
实际的言语交流依赖于连贯地按顺序表达各种单词和短语。然而,对相对较少的独立单词或元音进行模式分类,不能满足理解顺序语义信息的需求。为了解决这一问题,Schultz等人提出了一种基于连续表面肌电信号的语音识别音素建模方法:他们基于HMM构建了上下文依赖的音素模型,这种基于肌电信号的大词汇量语音识别系统在101个单词的词汇任务中实现了10%的WER。然后在中,HMM结合发音模型的三声子识别系统再次验证了基于音素的大词汇量连续无声语音识别的可行性。这些连续SSR系统的性能直接依赖于表面肌电信号的音素对齐。这个过程既复杂又耗时。对于长句,不能保证对齐的准确性。此外,通过语音和语言模型将音素序列映射到句子中需要大量的文本数据。这些问题使得有效、准确地理解与语音相关的表面肌电信号变得困难。
最近,一些先进的神经网络已经应用于表面肌电信号的小词汇量SSR,如卷积神经网络(CNN)、递归神经网络(RNN)和长短期记忆(LSTM)。然而,这些系统仍然停留在对有限数量的独立单词进行模式分类,不够智能和实用,无法理解语义信息。
在自然语言中,包括潜台词在内的音节和音素与单词或短语相比,代表着更细的信息。它们的序列可以组成各种短语或句子,为语言交际表达丰富的语义信息。因此,无声语音也可以在音节级别上解码,而不是单独的单词或短语的分类。一种智能实用的表面肌电信号SSR系统有望将语音相关的表面肌电信号直接解码为音节序列,从而更好地理解语义信息。
也就是说,有必要通过音节级解码而非简单分类来实现基于表面肌电信号的SSR,从而从表面肌电信号活动模式中细粒度地挖掘语义信息。近年来,序列到序列(sequence-to-sequence, seq2seq)模型由于其强大的序列数据处理能力,已被应用于一些自然语言处理(NLP)场景,包括语音识别、机器翻译和文本摘要。这些seq2seq模型通常由编码器-解码器结构组成。编码器将输入数据映射为高维表示,然后由解码器转换为最终输出。这种结构可以建立输入和输出数据之间的关系。此外,不需要使用fne粒度标签对数据进行精确对齐。模型将自己学习它们的对应。这些特性保证了它们在解码语音或文本等顺序信息方面的成功应用。例如,基于门控循环单元(GRU)的编码器和解码器在英语-法语文本翻译任务中取得了良好的效果。其次,采用多层长短期记忆(LSTM)替代GRU,并对输入数据进行倒序读取,提高了整体翻译性能。这些基于RNNs的seq2-seq模型在解码语音信号方面优于传统ASR系统。后来,seq2seq模型通过引入注意机制,可以更灵活、准确地关注关键信息,有效避免了因输入序列过长而导致过多信息的问题。与上述常见的seq2seq模型相比,一种完全基于自注意机制的新型seq2seq模型transformer在一些顺序解码任务中表现出了最先进的性能。这种自注意机制尽可能少地丢失重要信息,并帮助获取数据的全局关联,这在长期依赖问题上比LSTM更有优势。此外,由于不使用具有递归结构的rnn,模型可以并行训练,大大减少了训练时间。变压器模型也比上面提到的一些神经网络更易于解释。
最初,一些基于sEMG的SSR研究试图使用简单的模式识别算法对分离率单词进行分类。以下列出了一些有代表性的研究:Chan等人使用线性判别分析(LDA)对从受试者颈部和面部肌肉收集的0–9个数字的sEMG信号进行分类,并在听觉实验中实现了7%的单词错误率(WER)。后续研究报道,通过隐马尔可夫模型(HMM)模型分别建立了单独的韩语单词进行模式分类,识别准确率为87.08%。后来,九个分类器被用来识别阿拉伯语中最难的三个元音。结果表明,随机森林分类器表现最好,正确分类率为77%。
方法
下图显示了使用变换器模型从表面肌电信号解码无声语音的所提方法的框架。首先,对高密度电极阵列采集的表面肌电信号原始数据进行处理,得到特征序列;然后,通过变换器模型将特征序列解码为连续的音节级决策。最后,在语料库的基础上设计语言模型,生成接近自然语言的最后音节序列。
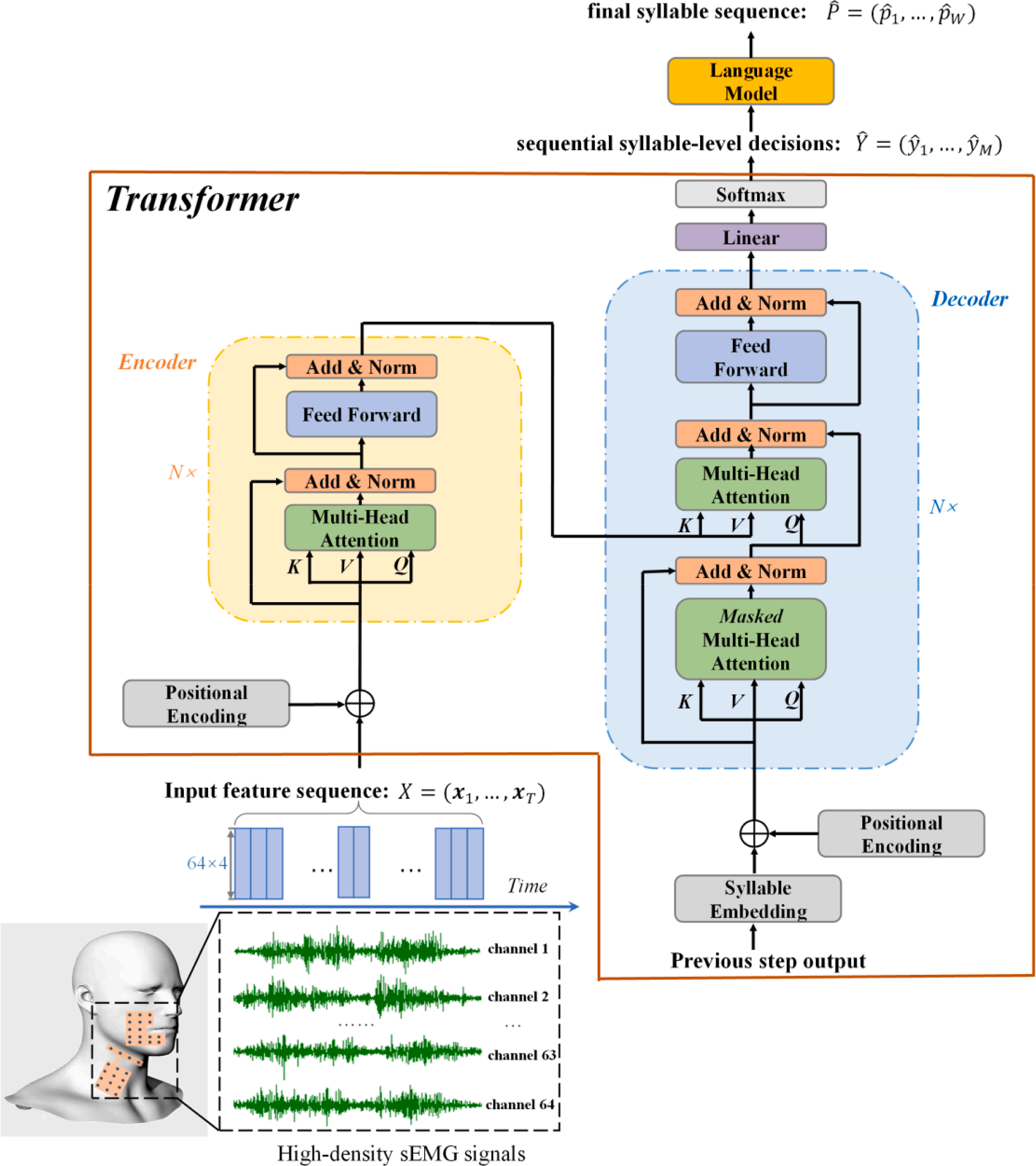
图1 所提出的使用变换器模型解码sEMG无声语音的方法的框架。sEMG特征序列X=(x1,…,xT)被输入到变换器模型中,然后被解码为顺序音节级决策Yõ=(y1,…,yM)。通过语言模型生成了最后一个音节序列“P”=(“p1”,“…”,“pW”)。、
为本次研究中高密度电极阵列的布置和规格。将两片32通道的柔性高密度电极阵列分别对称地安装在两侧的面部和颈部皮肤表面。每一块电极阵列都被设计成不规则的形状,以覆盖与人类发音有关的重要肌肉,包括面部肌肉(颧大肌、颧小肌、笑肌)和颈部肌肉(胸锁乳突肌、二腹肌前腹、颈阔肌)。每个电极直径为5mm,单极构成一个表面肌电记录通道。两个阵列中每两个电极的中心距离从10到18毫米不等。
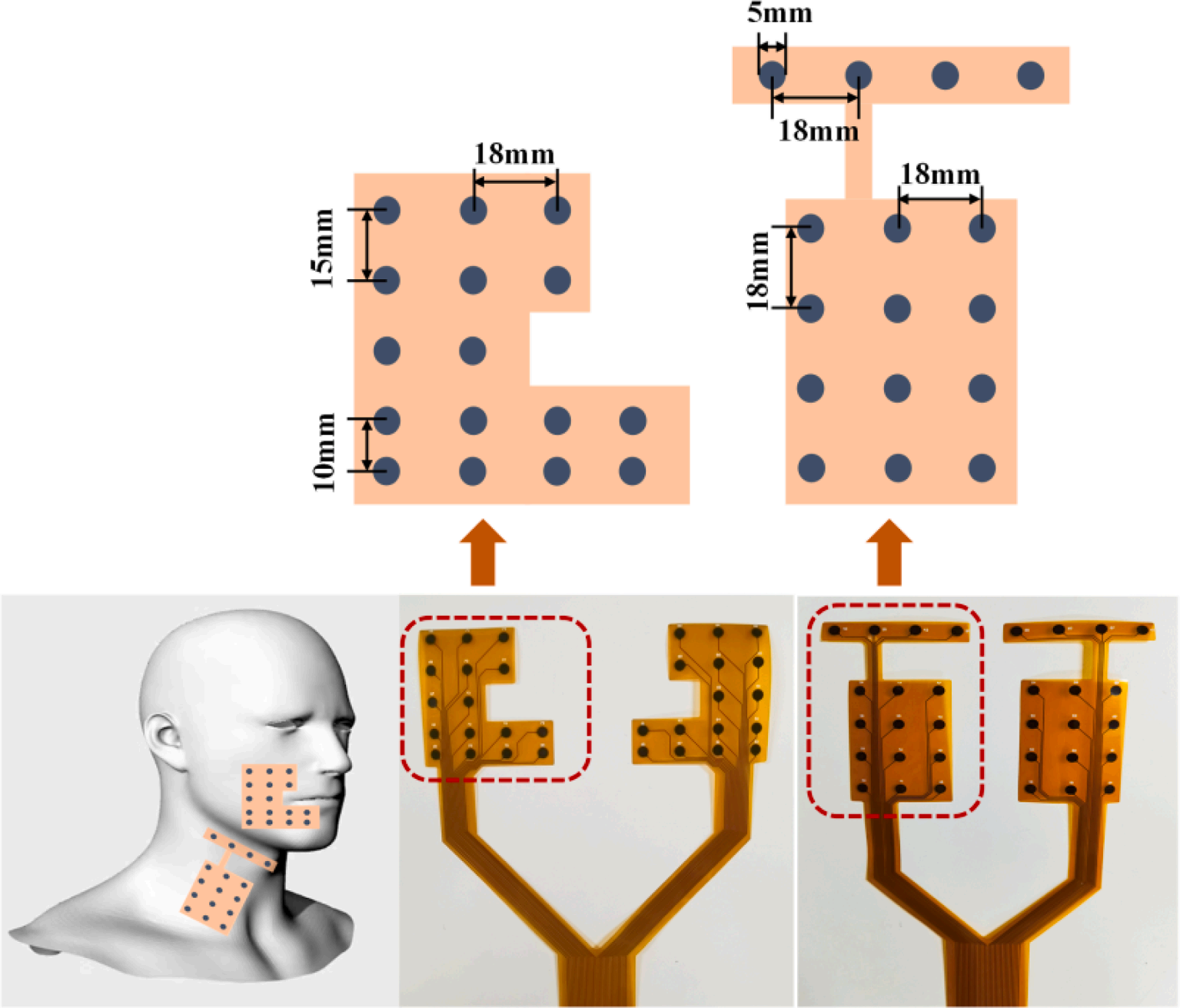
图2 高密度电极阵列的位置和规格。
信号采集实验前,所有电极均涂有导电凝胶,以保证电极与皮肤良好接触。用酒精垫清洁面部和颈部皮肤,电极阵列用医用级双面胶带固定在皮肤上。接地电极和参比电极分别置于耳廓两侧后方。实验是在一个安静舒适的房间里进行的。受试者被要求对语料库的内容足够熟悉,以避免在实验过程中出现语音错误。本研究语料库由智能家居、机械控制、消防救援等日常应用场景中的33个汉语短语组成,记为P1-P33。所有短语都是从82个汉字的字典中生成的。在汉语中,每个汉字对应一个音节。因此,直接用一个汉字来标注每个音节是很简单的。一个短语的音节/字符数从2到6不等。每个短语的发音可以看作是一系列不同的音节/字符。对于每个短语,受试者被要求默念20次。为了避免肌肉疲劳,每两次重复至少间隔3秒。
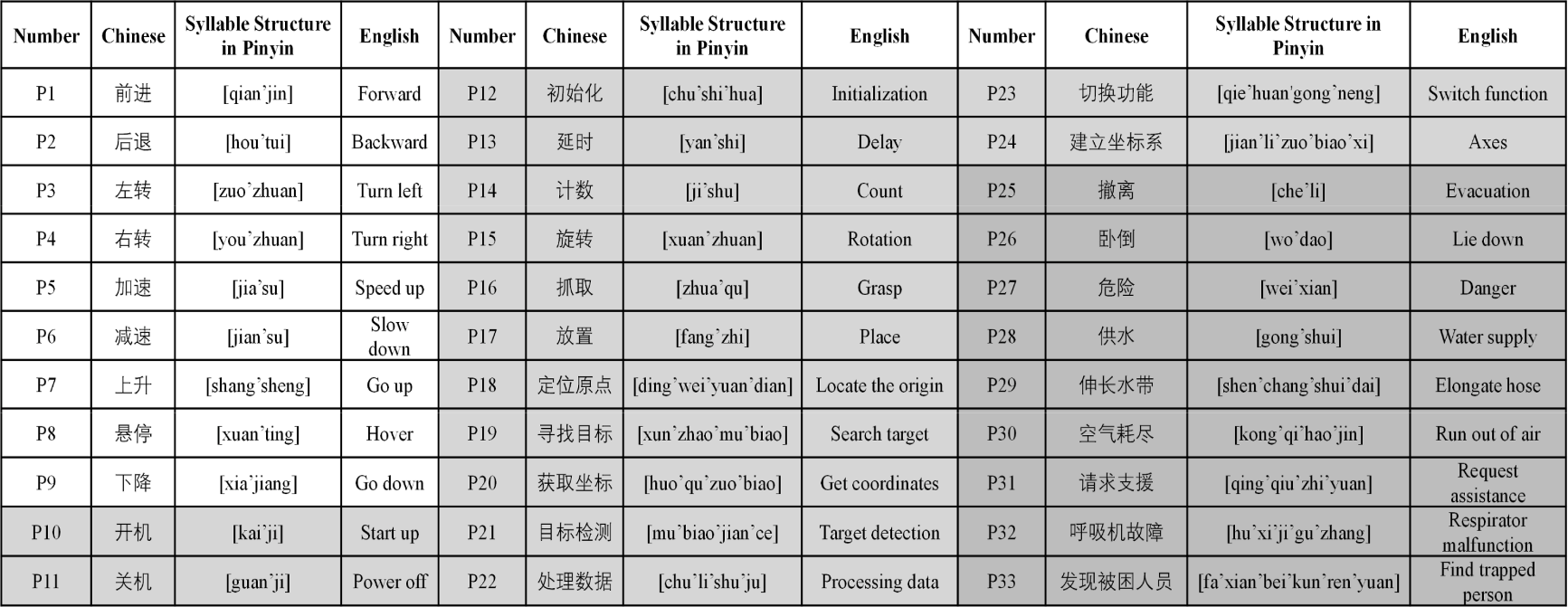
图3 语料库中33个中文短语的列表。
采用自定义多通道信号采集装置记录64通道表面肌电信号。每个通道信号经过内置的64 dB增益2级放大器和20-500 Hz带通滤波器后,由一个采样频率为1000HZ的16位a /D转换器进行采样。所有信号数据都存储在一台笔记本电脑上。随后,笔记本电脑通过高速无线网络将数据通过rtx3080ti gpu传输到云端服务器的工作站。所有任务都是在基于Python 3.6.1的PyTorch框架上实现的。图4显示了三个具有代表性的短语(即P1:“前进”,P18:“定位原点”,P33:“发现被困人员”)的多通道表面肌电信号波形,包含不同的音节/字符数。
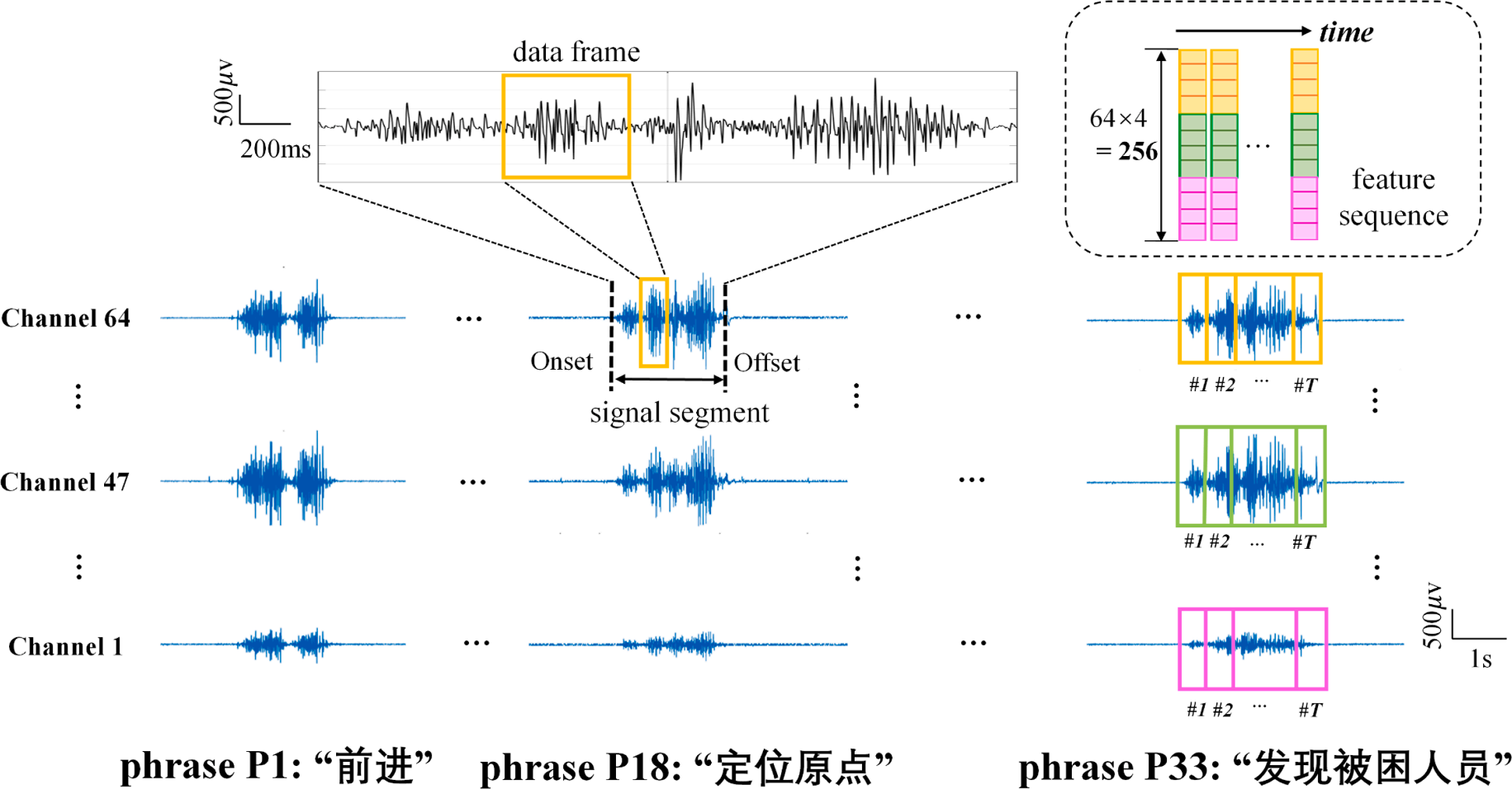
图4 三个代表性短语(即P1:“前进”, 第18页:“定位原点”, 第33页:“发现被困人员”), 分别地文中还介绍了数据分割和特征提取的过程。所有这些信号片段都是从第一受试者S1的数据中选择的。
数据分割
当进行潜声发音时,一系列连续的信号爆发代表表面肌电信号振幅的变化。因此,我们采用幅值阈值方法[33]来获取记录数据流中每个短语对应的表面肌电信号段。我们通常将阈值设置为平均值加上所有频道的emg基线(不含语音)平均值的三倍标准差。将信号的包络最初超过阈值的时间作为表面肌电信号段的开始时间,将包络低于阈值的时间标记为表面肌电信号段的偏移量(图4)。这样,每一个短语重复都被确定为一个表面肌电信号数据段,这也对应着本研究要识别的一个数据样本。最后,每个主题33个短语的样本总数为33 ×20 =660。
特征提取
首先,将每个数据段划分为连续的、不重叠的数据帧来表征序列信息。总帧数T经验设置为60帧。随后,对于每个数据帧,我们从每个表面肌电信号通道中提取Hudgin et al.提出的四个时域特征,包括表面肌电信号的平均绝对值、过零、斜率符号变化和波形长度。将所有64个通道的4个特征拼接起来,形成每个数据帧1 ×256形式的一维特征向量x。因此,对于每个数据段,得到一个特征序列X=(x1,⋯,xT),T=60,形式为60 ×256(图4)。
使用转换器器的无声语音解码
本文提出的表面肌电信号无声语音解码方法由转换器模型和语言模型组成。将短语级数据段的表面肌电信号特征序列输入变压器模型,然后解码成连续的音节级决策。然后,通过根据语料库构建的语言模型,将这些音节级决策调整为接近自然语言的最终音节/字符序列。
结论
转换模型被应用于从表面肌电信号解码无声语音,因为它具有在细粒度音节水平上表征语义信息的强大能力。在所测试的SSR方法中,所提出的序列解码方法获得了最低的CER和最高的短语识别精度。实验结果验证了基于表面肌电信号的SSR序列解码方法的可行性。该研究为促进SSR的实际应用提供了有价值的工具。
如果您对表面肌电方面研究感兴趣,请与我们联系!
声明:文章仅用于学术交流,不用于商业行为,若有侵权及疑问,请后台留言,管理员即时删侵!
