高密度表面肌电(HD-sEMG)在无声话语识别中的应用
背景
语言表达是人类参与生活、工作的一种重要的工具,通过发送、接受清晰的语音信号,人们可以明确地理解别人的意图,并予以反馈。高质量的语音信息对于大脑的解码来说尤为重要,若是在语音发送、语音传播、语音解码的任意环节出现问题,都会导致语音信号的接收不完全,对正常交流造成恶劣影响。根据 2006 年全国第二次残疾人抽样调查结果,我国现有 8296 万残疾人,其中言语残疾人口有 127 万人,占总残疾人口数的 1.53%。言语残疾造成的沟通不便,严重降低他们的生活质量,影响他们的日常生活交流,对他们的家庭和社会都是沉重的负担。因此,帮这部分言语残疾人建立与健康人群的语言纽带迫在眉睫。而这些言语障碍残疾人中,有一部分属于发音肌肉功能比较完整、但声带受损的,如果可以利用他们发音肌肉的活动来识别发音内容就可以重建他们与外界的沟通。对于一些声带使用过度的人群,如职业歌唱家、教师等,同样存在不发出声音的情况下与他人进行良好沟通的需求。
在军队或银行等特定的机密场所中,使用可听的语音进行交流可能会暴露敏感信息。例如特种部队士兵,可能需要依靠无声通信来进行秘密行动。同时,在水下工作、火灾现场、辐射现场等,一线救援人员通常会穿着防护服,不能透过防护面具发出清晰声音。人们希望能在不发出声音的情况下发送、接收到同伴的沟通意图。
在科技飞速发展的现代社会,人们不仅需要直接通过听觉系统听到言语信息,还需要通过间接的形式获取语音内容。因此,自动语音识别(Automaticspeech recognition,ASR)技术就此产生。语音信号伴随着发音动作的进行而产生,一直被广泛应用于基于人的语音输入的语音识别系统中,如微信中的语音转文字功能、讯飞的语音转文字输入法。然而,由于语音信号极易受到环境噪声和人为干扰的影响,在很多场景中很难被高质量地采集到,语音内容自然也很难精确识别出来,人们需要一种不易受到环境噪声干扰的语音内容识别技术。
针对以上三类问题及需求,有很多研究进行了基于表面肌电信号进行无声语音识别的探索,利用表面肌电信号稳定、不易干扰的优点,对无声语音信息进行精准识别。从而保证残疾人在无需发出声音情况下也能表达自己的意图,让私密场合里的人们之间的交流只需动动嘴巴而不必发出可听语音,使嘈杂环境中的发音信息也能被清晰地识别成“可视化”内容。

基于高密度肌电信号的无声语音识别系统应用场景
基于表面肌电信号的语音识别技术
发音是一个极为复杂的生理过程,是由语音器官的协调运动所引起的相关肌肉相互配合收缩、放松来控制的,整个过程涉及面、颈部40多块肌肉。人类可以通过控制肌肉的协同模式,有意识地、明确地表达自己的意图。当人们在进行说话的动作时,参与发音的肌肉被激活,相应地会产生肌肉电信号。发不同的音时,激活的肌肉、能量存在一些差别,利用这一特点可以从不同发音过程中采集肌电信号并进行特征提取以识别发音内容。
基于sEMG信号进行语音识别有一个较为规范化的过程。首先要同步采集发音过程中的sEMG信号,然后对采集到的信号做预处理。之后提取合适的特征并输入分类器进行大量、多次的训练,建立sEMG信号与人类自然语音的映射关系。在训练过程结束后,就可以输入测试数据集也就是新的sEMG信号进行分类识别,读取到人类在这段sEMG信号中“说的话”。
高密度表面肌电采集与预处理
受试者在进行无声发音任务时,肌电数据的采集不易受到外界环境的干扰,但为了让受试者保持良好的生理和心理状态,实验被安排在屏蔽房中进行。为降低电力所带来的工频干扰,屏蔽房中除实验设备及灯光,其余所有电源均被切断。屏蔽房内摆放一把椅子供受试者坐下,同时在椅子前面的桌子上摆放一个显示器,通过展示发音波形向受试者进行发音任务提醒。

实验室环境
电极分布位置
由于电极数量和位置对于采集到的包含发音信息的肌电信号质量有着巨大影响,过少的电极不能完整覆盖与发音相关的所有面颈部肌肉,过多的电极采集到的数据会存在冗余。在综合考虑了受试者的面、颈部宽度以及发音相关的肌肉位置后,本实验确定在受试者面颈部共贴上120个电极。其中,面部基于面中间位置对称的左右两侧各贴上4×5(行×列)个电极,颈部基于颈中间位置对称的左右两侧各贴上5×8(行×列)个电极。电极的直径相同,为10mm。相邻电极之间的距离相等,中心点的距离约为15mm,以保证采集到的信号独立。
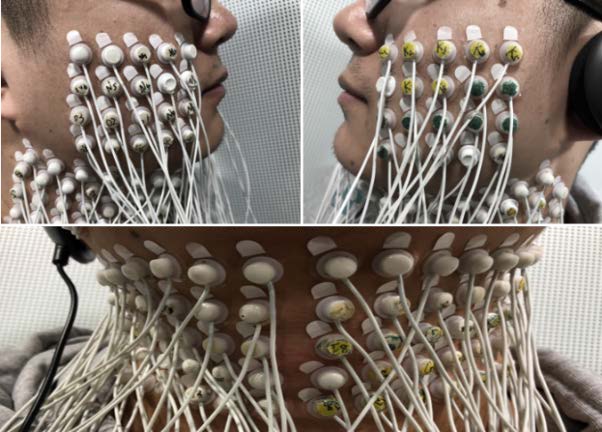
120通道高密度肌电示意图
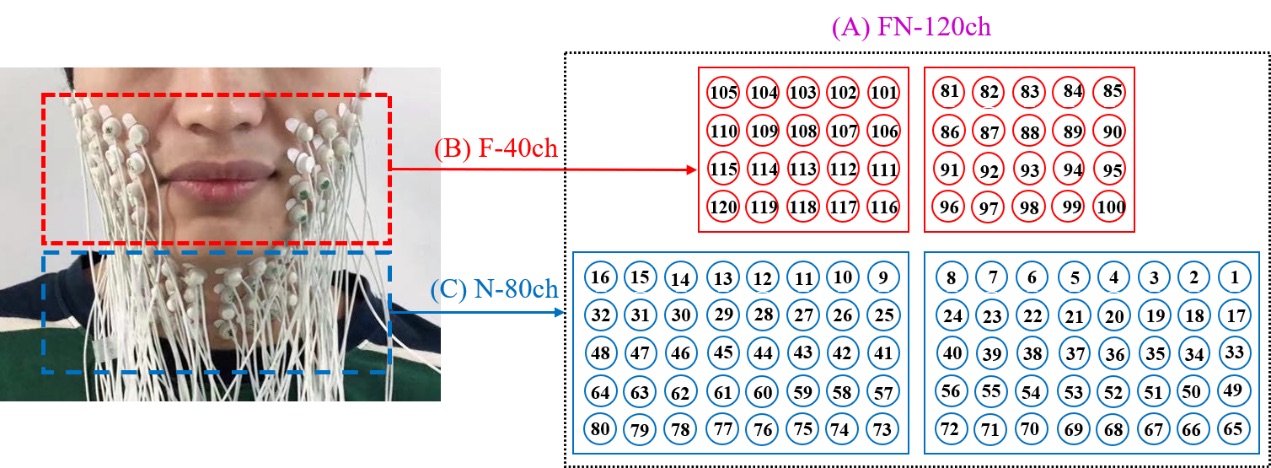
面颈部电极阵列分布示意图及其分组
实验过程
每一组包含28次发音,为防止受试者出现发音疲劳的状况,该过程被分成两次进行,在14次发音后实验员会示意受试者休息1min。受试者按照显示器上提示的波形进行3s静息、1s发音、3s静息、……、3s静息。其中间隔的3s静息是为了让发音肌肉休息,避免肌肉疲劳。
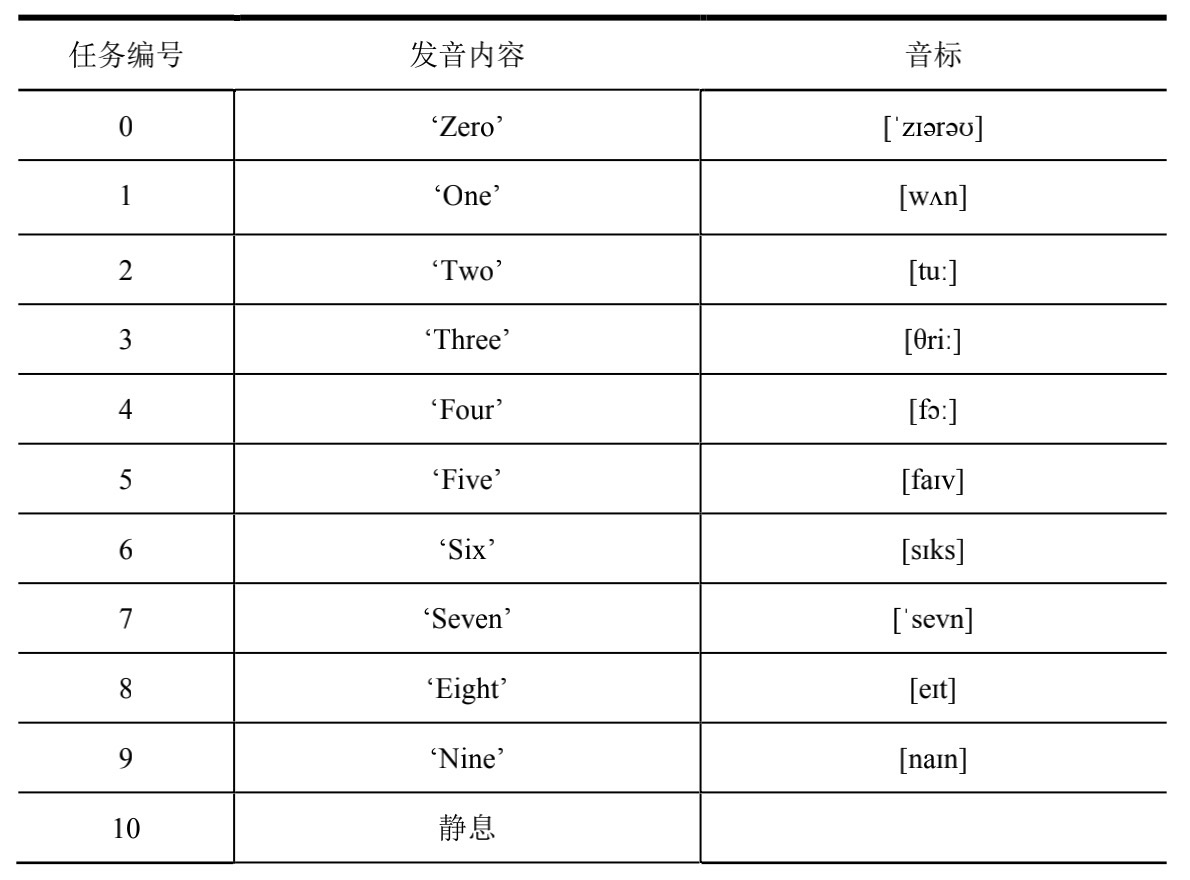
发音任务

实验流程图
高密度肌电信号的预处理
HD sEMG 本质上是多个通道的表面肌电信号的汇总,而表面肌电信号作为一种非平稳的时序电信号,在采集过程中容易受到外界信号的干扰。因此在对肌电信号进一步分析之前,应进行滤波处理,获取纯净的肌电活动数据。同时,由于实验中的发音任务不是连续的,在特征提取之前需要将完整发音过程的数据单独分割出来再进行拼接操作,从而得到完整的、具有一定数据量级的发音数据。
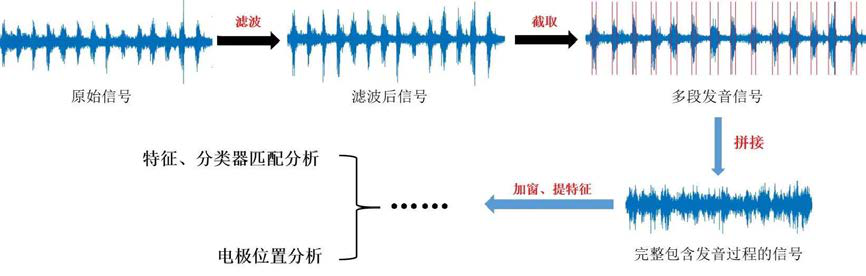
预处理流程图
首先将12 个特征与3种分类器进行匹配,并提出4个评估标准对识别性能进行分析。结果显示,线性判别分析(LinearDiscriminantanalysis,LDA)和支持向量机(Support vectormachine,SVM)在本文数据集中的表现明显优于K最邻近结点(K-nearest neighbor,KNN),LDA和SVM的分类性能不相上下,但SVM匹配所有特征时的运行时间都要长于LDA。因此,LDA更适合本文数据集的语音识别。同时,在LDA所匹配的12个特征中,波形长度(Waveformlength,WFL)能实现最高分类精度、敏感度和F1分数,在它的运行时长仅比其它特征略高1~2s的情况下,可以认定WFL实现了与LDA的最佳匹配。
总结
对称位置通道sEMG信号的分析显示,发音过程中对称位置的肌电信号变化存在高度一致性。并且,单独使用左侧范围和单独使用右侧范围通道的肌电信号的分类精度高度一致,说明了对称位置通道可能包含了相同的肌电变化信息,无需重复采集。最后,通道排序的结果说明了对于不同受试者都可以使用少量电极达到较好的识别性能,具体的通道数量、位置要因人而异,但是从生理角度去选取通道位置是有一定价值的。
基于高密度表面肌电信号的无声语音识别研究,可以为后续无声语音识别时特征、分类器的选择提供参考,同时为标准化电极位置、数量的选取打下基础。
言语发声神经电信号测量系统

当前大多数利用表面肌电信号进行语音识别的研究中,存在使用的电极数量少、位置选取不够科学的问题。高密度肌电设备对语音识别时电极位置对识别性能的影响进行分析,来达到更好地选择电极位置和数量的效果具有不可替代的作用。
同时在神经工程领域,越来越多的研究尝试同步采集脑电与肌电的信号,用来探索包括发音在内的运动意图由大脑传递到肌肉执行的过程中潜在的规律。高密度脑肌电测量识设备使得研究情绪,肌肉活动到最终发音的全过程研究与实验成为可能。
Speech HD-64 型言语发声神经电信号测量系统是一套采集语音过程中的脑/肌神经肉肌电信号的设备,并可通过后端的分析软件,以及与力学、运动学设备的同步信号分析,开展语言学、无声通信、言语障碍、人体运动特性、模式识别、假肢设计、虚拟现实等多领域的研究工作。

分散式高密度肌电,每组4、8、16通道传感器(最大256通道)

脑电模块(可同步实时采集高密度脑/肌电)
言语发声神经电信号采集分析软件
主要优势:
1、多模态数据同步模块,可实现多种信号实时同步传输;
2、可配置设备的采集参数,实现数据同步采集功能,可显示实时波形、实时频谱图、实时电势图和3D模型姿态;
3、自定义动作序列播放功能,并用Mark点标记动作事件信息;
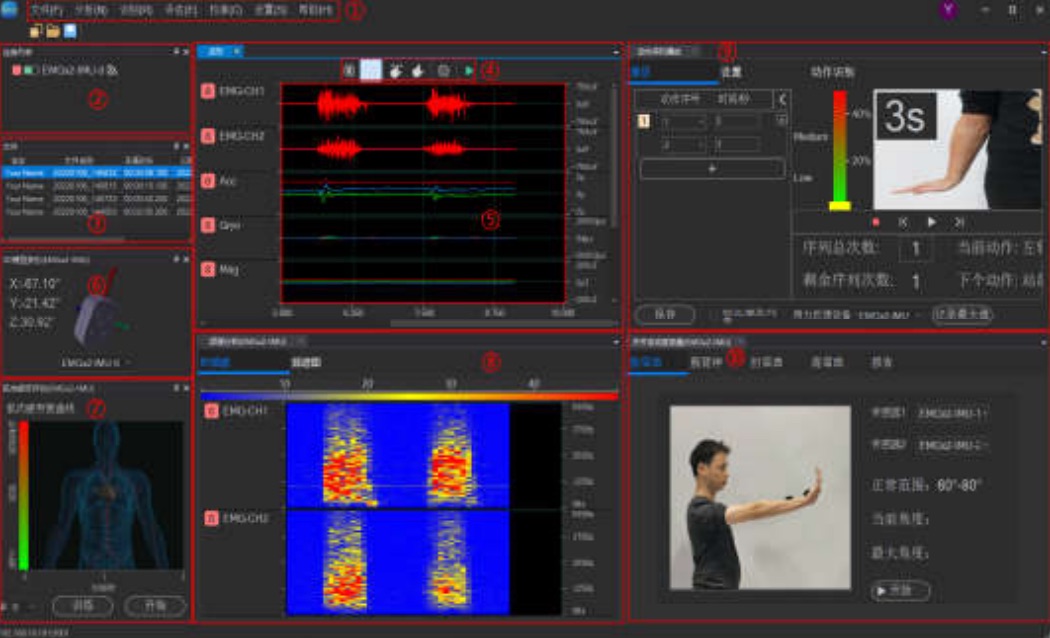
软件操作界面
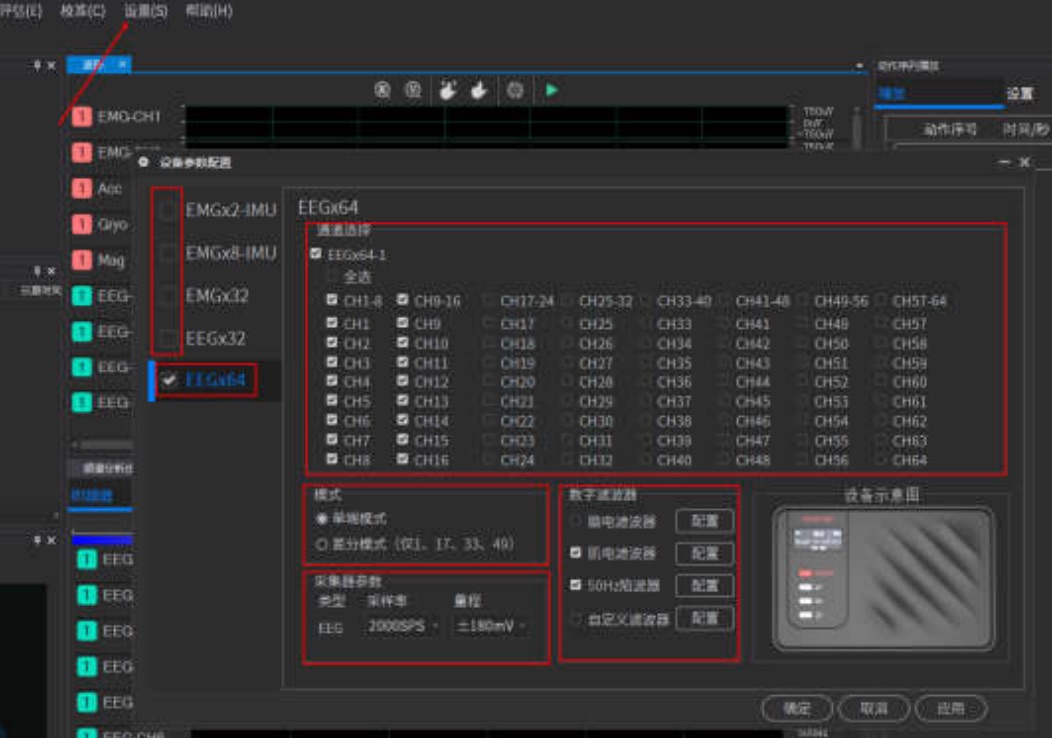
支持肌电、心电、脑电、惯性信号、血氧、血压的多种信号联合采集,并配置设备采集参数

实时显示设备的连接状态、电量和信号强度
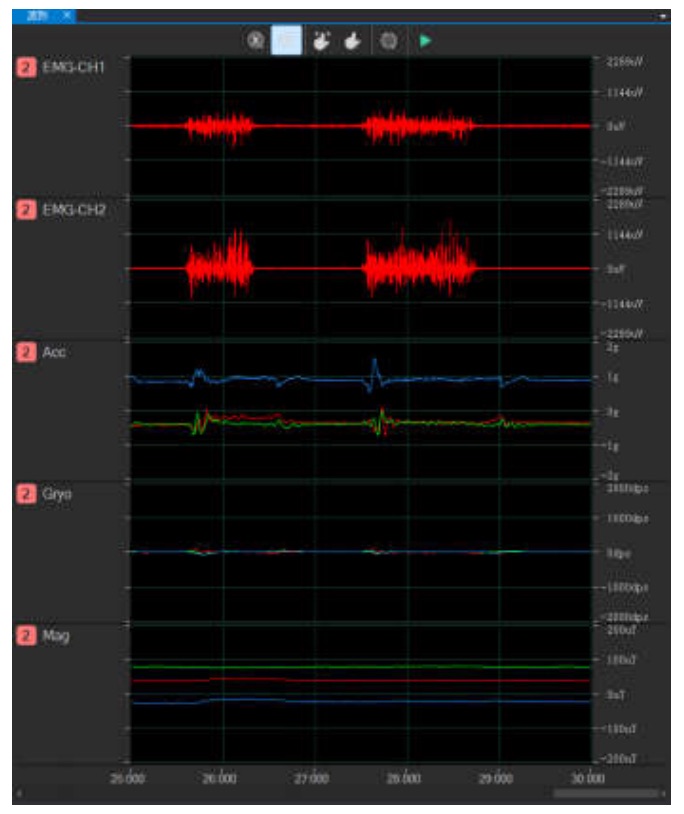
实时显示波形
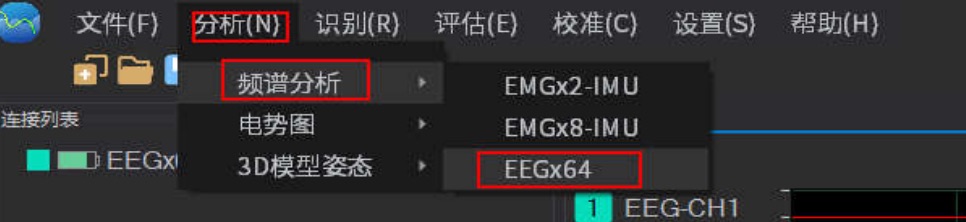
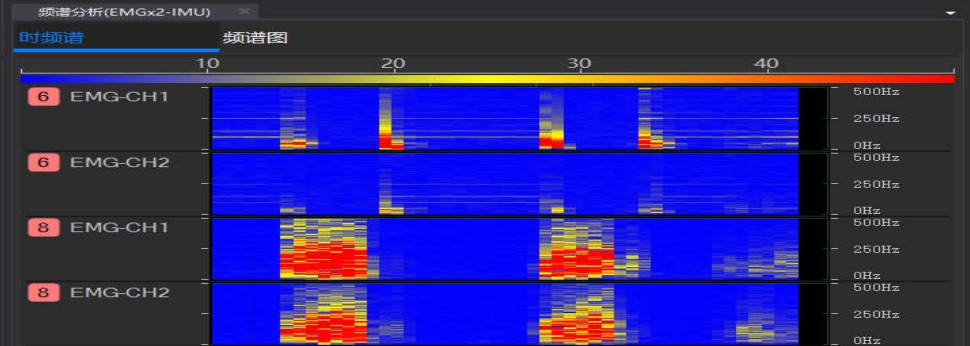
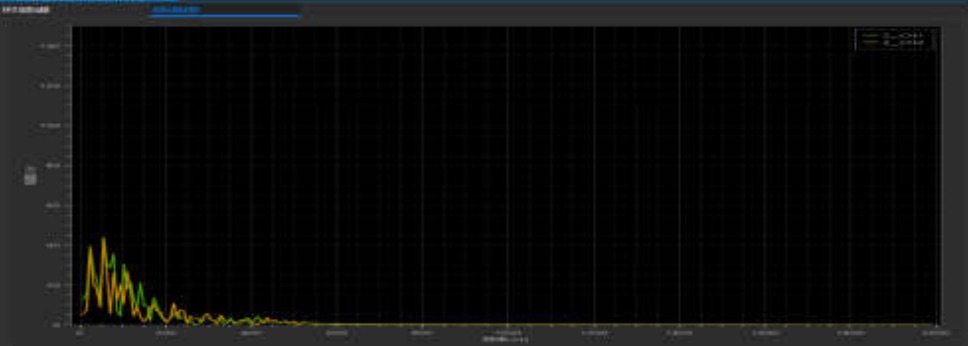
实时频谱图、时域频谱
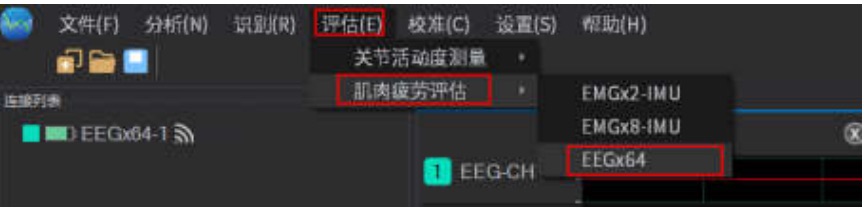
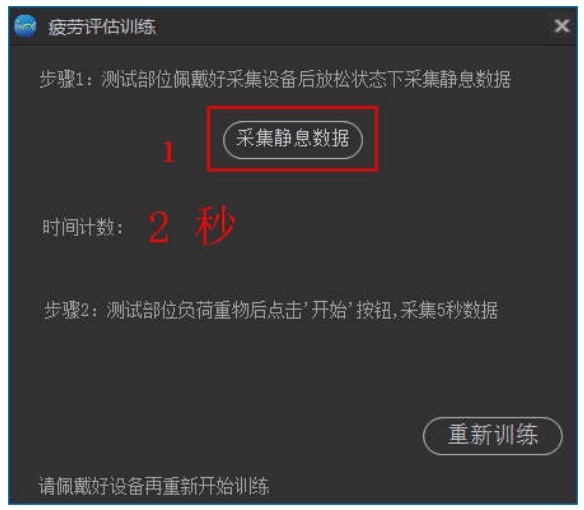
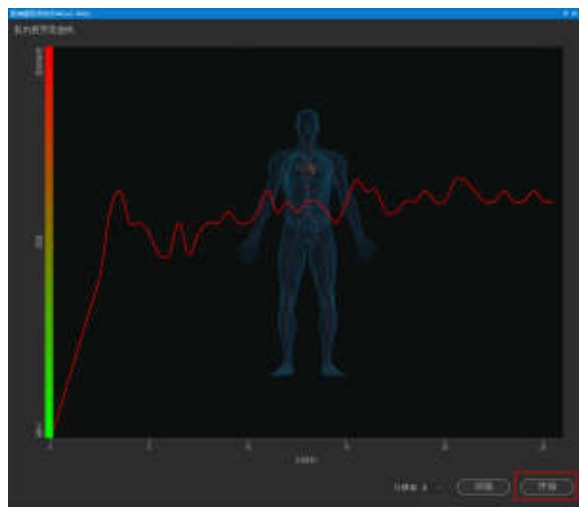
肌肉疲劳分析

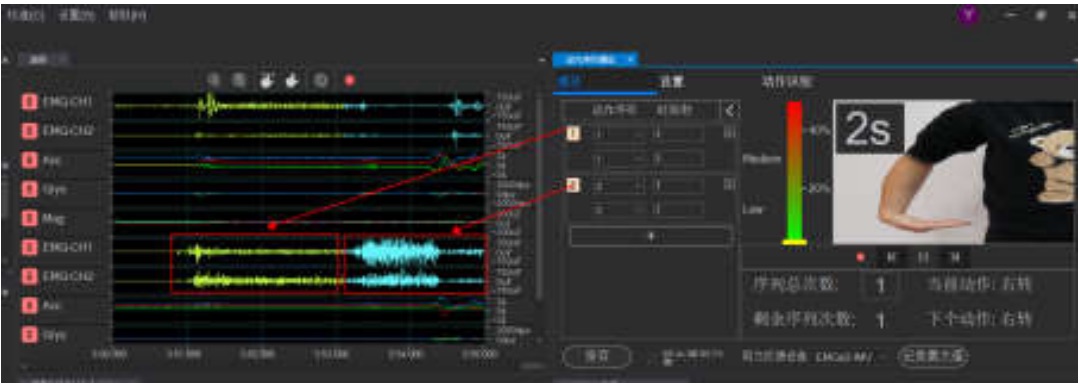
自定义动作序列播放功能,并用Mark点标记动作事件信息,不同动作序列用不同颜色表示
如果您对言语研究感兴趣,请与我们联系!
声明:文章仅用于学术交流,不用于商业行为,若有侵权及疑问,请后台留言,管理员即时删侵!
